
Data Models in RunningMate
What is a predictive data model?
A predictive data model helps us predict the probability of a certain outcome, such as someone’s race, likelihood to turn out to vote, or likelihood to vote for Democrats. These models are mathematically predicting the likelihood of an outcome on a scale of 0-1. The more likely the outcome is to be true, the closer the number will be to 1. Predictive models are made by analyzing training data, and they are predictions (not assurances).
How does RunningMate use data models?
RunningMate has several predictive models:
- Partisanship score (“Party Lean”)
- Turnout score
- Race
We use these models to predict information about the targets in a user’s district. These predictions are informed by data we have about that state/area.
What do RunningMate’s data models show us?
Our partisanship model predicts how likely it is that someone will vote Democratic. The higher their score, the more likely they are to support a generic democratic candidate. This data model is based on:
- A person’s actions (when we have access to that information), such as party registration and voting history in primaries, midterms, and general elections.
- A person’s demographics
- A person’s location
RunningMate's Partisanship Model: Party Lean Model
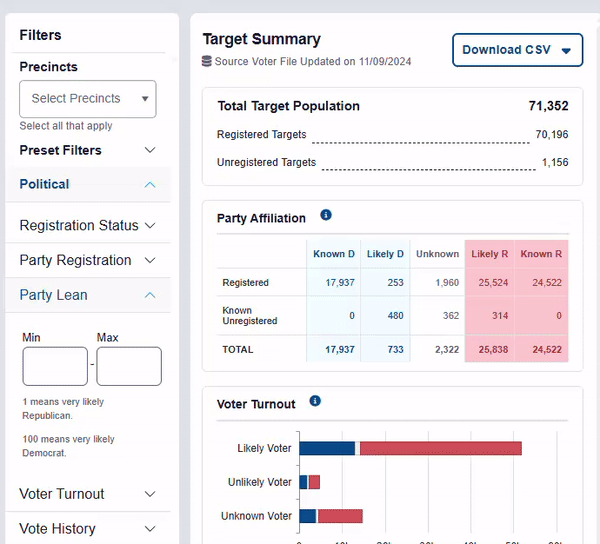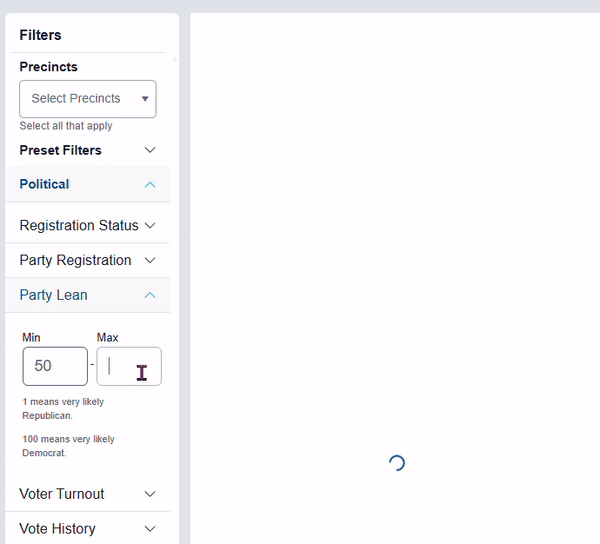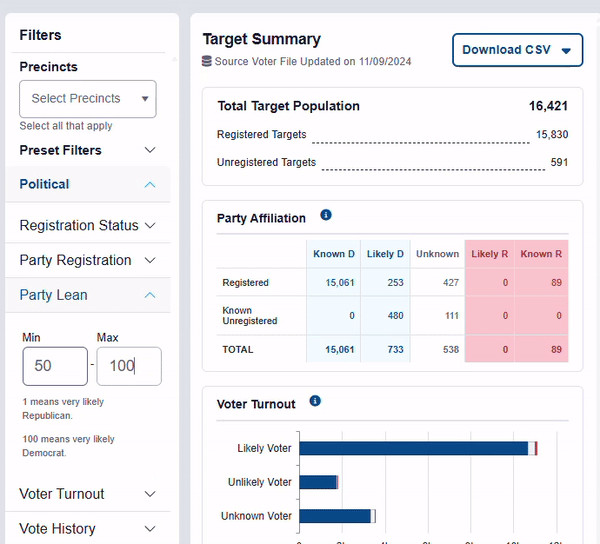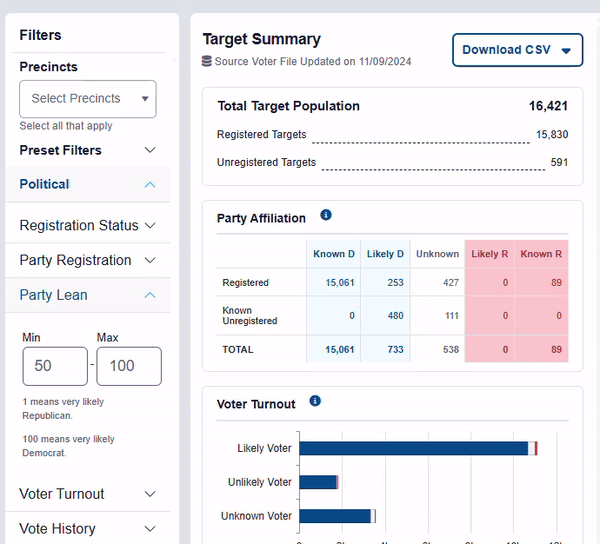
Users will encounter our partisanship model when they interact with the “Party Lean” filter on RunningMate. The closer a person’s score for Party Lean is to 100, the more likely they are to vote democratic.
RunningMate's TurnOut Model: Voter Turnout Model
Our turnout model predicts how likely a person is to vote. The higher their score, the more likely they are to vote. This data model is based on:
- A person’s registration status in previous elections
- A person’s vote history
- A person’s demographics

By looking at people’s previous patterns and behaviors, we predict how likely it is that they will vote in future elections. A user will encounter this turnout model in the filter section.
RunningMate's Race Model
Our race model is how we predict the likelihood of a person’s race, giving us the probability for several different racial options (Asian, Black, Latino, White, and Other). This data model is based on:
- A person’s location and the demographics of that area, obtained via Census data.
- A person’s name (first, middle, and last)

Users will encounter this model when looking at our filters for race. While some states provide information about race, such as with certain voter files, we predict race for instances when it is not provided.
What does a user need to know about our data models?
It’s important to remember that our data models are framed from a 0-1 scale. The higher a number, the more likely the outcome of that predictive data model will occur.
These probabilities are informed by the data and information we have about a district, and are probabilities, not known facts. Data varies by state, and therefore our models vary. Some states provide vote history and party registration, some do not. Some states provide racial data, some do not.
Because this data varies by state, it is important to approach understanding a user’s data within the context of their state and what is provided.
What are some of the limitations of our data models?
When compared to the voter file, the PIR (likely unregistered) data has less information about individuals. What we know about unregistered voters is driven by the area in which they live (and sometimes some demographic information). This means our ability to predict information about them is more limited. For example, if someone lives in a consistently blue area and they are unregistered, it is unlikely that they will show up as likely republican for party affiliation.
You know your district better than we do, and the models used in RunninMate are predictive not concrete. RunningMate enables users to upload and update the data we have on the voters in the district with their current support scores and data tags.
